Kicking the Stack with Terraform Stacks and Day 2 Ops: Dealing with Friction between Component Dependencies
Managing Day 2 operations with complex Terraform stacks is never entirely seamless — especially when components span multiple regions and contain live interdependencies. In this setup, even something as routine as tearing down a component can become fragile and fail for unexpected reasons.
This post explores a specific problem: Terraform’s insistence on evaluating data sources during plan, even for components marked for removal. It causes plan to hang or fail entirely when a dependent system — like a container app serving an OpenAPI specification — is temporarily unavailable.
Stack Overview
This Terraform stack is composed of three main components, deployed in a layered, dependency-driven sequence:
1. Global Component
The global component houses shared, multi-region infrastructure. It includes things like:
- ACR Tasks, which build container images in Azure Container Registry when code is pushed to long-lived branches.
- Cosmos DB containers used by applications, though not the database account itself, which is shared across regions. These are foundational resources used by every regional deployment.
2. Regional-Stamp Component
A regional-stamp represents a single, self-contained deployment of the application to one Azure region. You can have one or many of these — each deploying a full instance of your app, including compute, networking, and any region-specific configuration.
Each stamp relies on global for shared infrastructure like image builds or shared database containers.
3. API Component
Finally, the api component configures Azure API Management (APIM) to front the application. It performs two main tasks:
- Creates load balancing policies in APIM that route traffic to each regional stamp.
- Updates the OpenAPI specification for the API in APIM, pulling it from a live endpoint exposed by the primary regional stamp’s Container App.
The deployment sequence flows in this order:
global → regional-stamp(s) → api
Each step has clear dependencies on the previous one. The api component, for example, needs the regional-stamp Container App to be running and serving the OpenAPI specification before it can update APIM.
Not all of these dependencies are deploy-time dependencies. Some of them are runtime dependencies.
The Problem: Data Sources Break When a Dependency Goes Down
Things fall apart when one of these dependencies becomes temporarily unavailable — for instance, if the Container App that serves the OpenAPI spec in a regional stamp goes down.
Inside the api component, a Terraform data source is used to fetch the OpenAPI JSON:
data "http" "openapi" {
url = "${var.endpoint}/openapi/v1.json"
}
This source pulls the live OpenAPI definition from the running container app. But if that app is unavailable — even briefly — Terraform plan fails, because data sources are evaluated during the planning phase. You can’t even start a destroy or refactor operation if Terraform can’t resolve the data.
This becomes a blocker when you want to remove or replace the api component. Even if you comment out the component and declare it as removed like this:
removed {
source = "./src/terraform/api"
from = component.api
providers = {
azurerm = provider.azurerm.this
http = provider.http.this
}
}
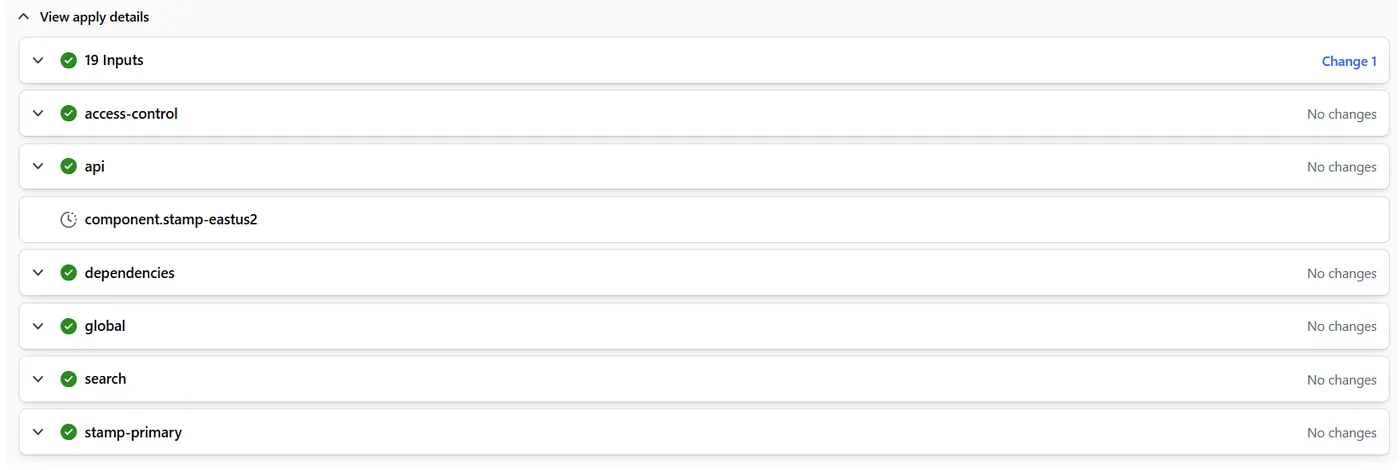
Terraform still tries to evaluate the data source during plan. It doesn’t matter that the component is marked for deletion — terraform plan still reaches into the component and attempts to resolve the data source, which fails due to the missing dependency.
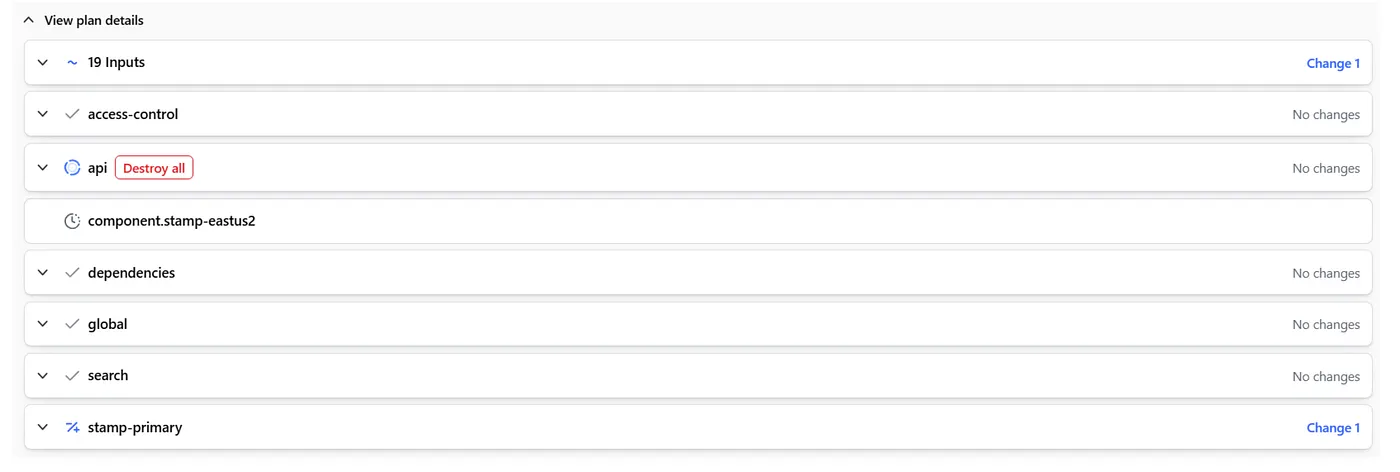
Notice how it does know that it wants to destroy everything in the api component. Yet, it is still going to process the Data Sources. Because it can’t access the Data Source, it eventually it craps out and produces this:
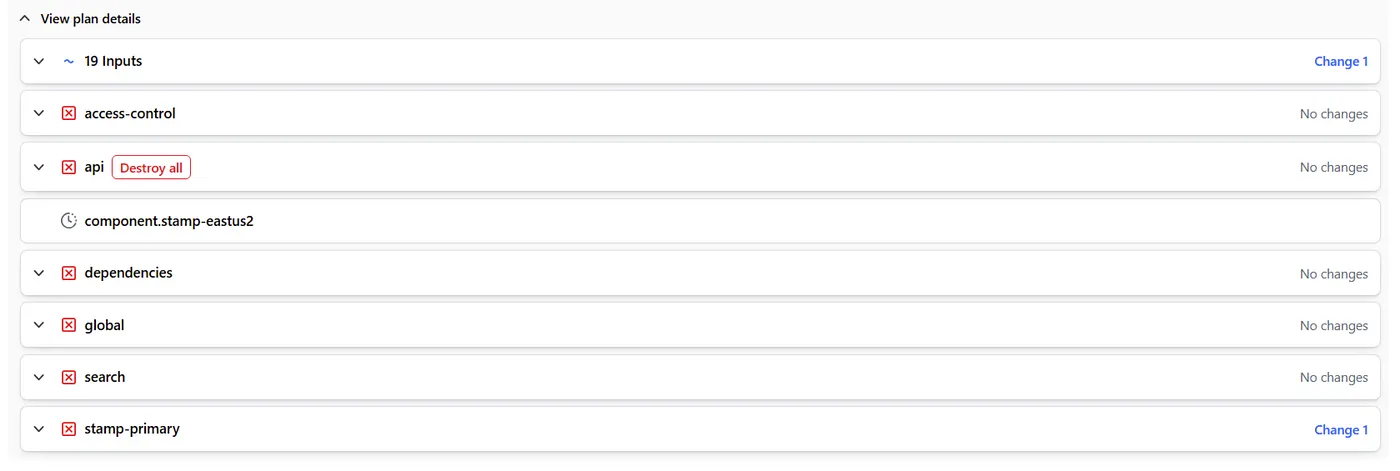
The Workaround: Hollowing Out the Component
Since Terraform doesn’t short-circuit data sources in removed components, the only viable workaround is what I call the Kansas City Shuffle.
You leave the api component block in place, but go into the module and remove or comment out everything — resources, data sources, and logic — leaving only the module inputs and minimal outputs (if required for dependency resolution).
In effect, you’re telling Terraform: “This component still exists, but it doesn’t do anything right now.”
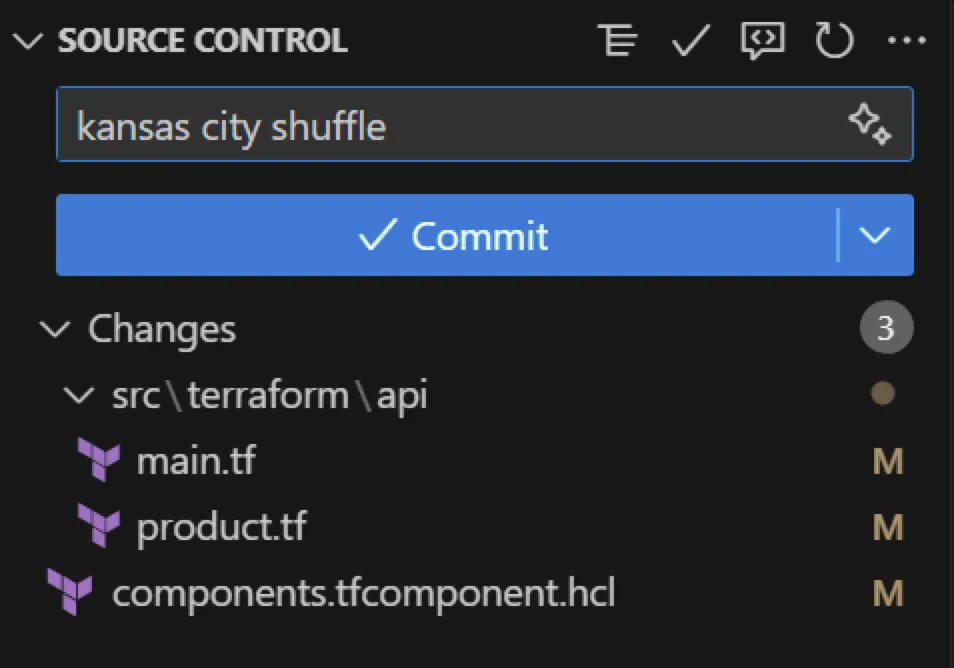
The result is that plan can succeed because Terraform no longer tries to evaluate the broken data source. The apply goes through cleanly, tearing down the real resources without evaluating external dependencies.
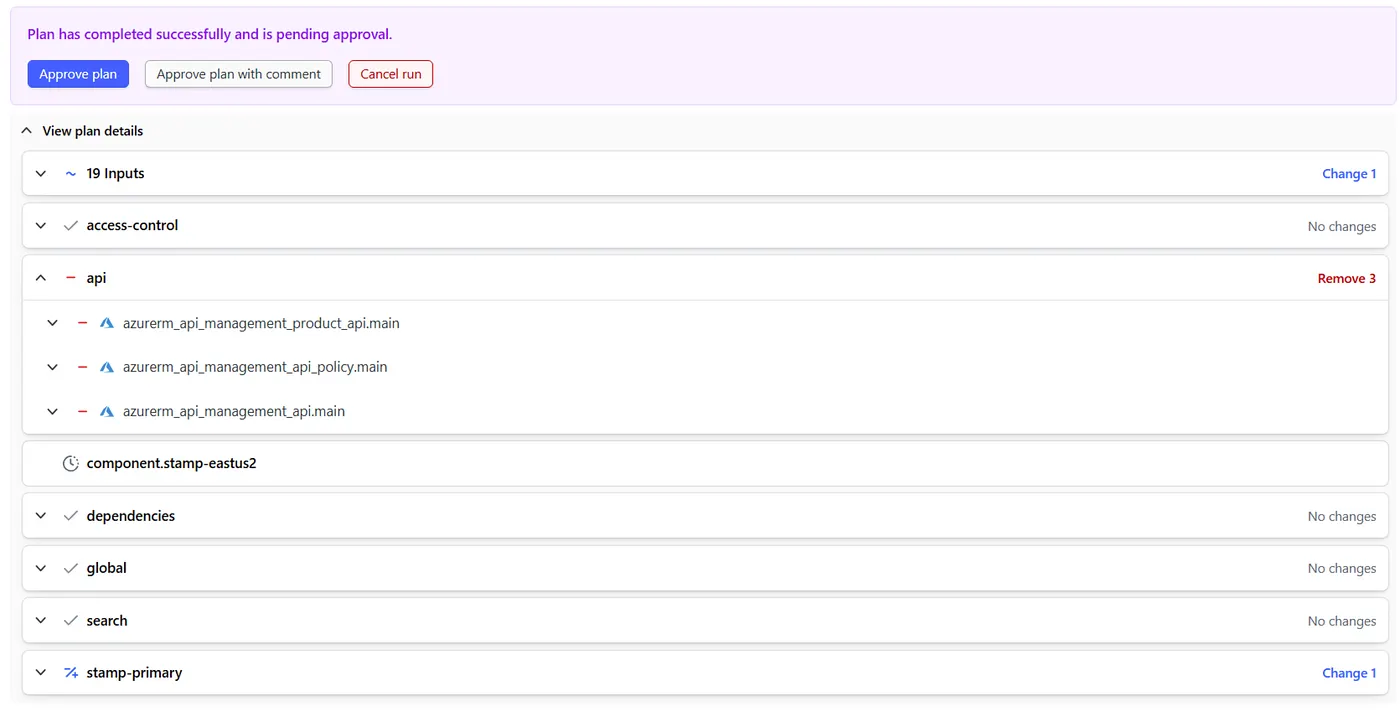
The apply is also successful. When I am done and the dust settles and my workload comes back online (in this case it’s a Container App) then I can uncomment out everything in api and bring it all back — essentially reversing the shuffle.
It Shouldn’t Work Like This
There’s no good reason for Terraform to evaluate a data source in a component marked for destruction. That logic should be bypassed — especially in tools like Terraform Stacks, where component lifecycle management is a core feature.
So until HashiCorp addresses this, you’ll need to manually hollow out components when one of their data sources relies on a resource that is temporarily offline.
Conclusion
This issue illustrates one of the subtle ways Terraform’s plan-time evaluation model can get in the way of Day 2 operations — especially in distributed, multi-region systems. As infrastructure grows more interconnected and dynamic, tooling needs to be more resilient to partial failures.
Terraform’s current implementation of behavior during plan isn’t well-suited to that reality. But with a few workarounds — and some patience — you can keep your stack operable even when parts of it go dark.
And HashiCorp, if you’re listening: skipping data source resolution for components scheduled for removal would make stack workflows significantly more robust.
