Data Plane Whack-a-Mole: No ARM, No Bicep, No Problem? Terraforming Azure AI Search with Terracurl
Infrastructure as Code (IaC) has become a cornerstone of modern cloud architecture, yet even in mature platforms like Azure, critical gaps still exist — especially when it comes to data plane resources in services like Azure AI Search.
While ARM templates, Bicep, and Terraform are powerful for provisioning infrastructure, they fall short in scenarios where no ARM resource definitions exist. There is an entire supply chain process where a resource (either control plane or data plane) needs to be represented in ARM, then generated in a language-specific SDK (golang SDK for Azure) and then resources developed for it in the azurerm Terraform provider. Bicep and AzAPI bypass two steps in this supply chain process allowing for “Day Zero” support — but what is Day Zero? Day Zero means being supported by ARM! What happens when resources haven’t even been onboarded to ARM properly? Frankly, this should be part of the Definition of Done (DoD).
One such painful omission is the ability to define and deploy AI Search indexes — the core building blocks of the service — using any native IaC tooling.
This article outlines how I overcame that limitation using terracurl, a Terraform provider that lets you define arbitrary REST API requests. I detail my trial-and-error process of creating an Azure AI Search index, resolving various schema issues, refreshing tokens, and ultimately achieving a working configuration.
The Initial Frustration: No ARM Support for Azure Search Indexes
While trying to automate Azure AI Search index creation, I ran into a frustrating reality: data plane resources like indexes cannot be defined using ARM templates, and therefore, cannot be managed through Bicep, AzureRM, or even AzAPI. This makes these indexes invisible to all native Terraform tooling as well.
That’s when I discovered terracurl, which allows you to send HTTP requests directly from Terraform. Since it can orchestrate REST API calls, it fills the exact niche that ARM doesn’t cover—allowing me to create the index via the Azure REST API.
Getting a Response from the Service
At first, I couldn’t even inspect the full error message returned by the Azure Search REST API. By default, terracurl only considers 200/201 status codes as successful. But to debug properly, I needed to allow non-success codes like 400 (bad request) and 409 (conflict) to be treated as valid for response inspection.
response_codes = [200, 201, 400, 409]
With that change, I could now output and examine the raw responses:
output "create_index_status_code" {
value = terracurl_request.create_search_index.status_code
}
output "create_index_response_raw" {
value = terracurl_request.create_search_index.response
sensitive = true
}
output "create_index_error_message" {
value = try(jsondecode(terracurl_request.create_search_index.response).error.message, null)
}
This allowed me to at least look at the errors I was getting and make refinements to the JSON schema I was submitting. Unlike Terraform or even Bicep documentation working directly with Data Plane Resources you have to essentially look at lightly documented REST API documentation. Very few examples, zero practical examples and documentation that looks more like C# or Java Object structures than configuration.
https://learn.microsoft.com/en-us/rest/api/searchservice/indexes/create?view=rest-searchservice-2025-09-01
Resolving Index Schema Errors
The initial error I encountered indicated that the API couldn’t find the properties key:
create_index_error_message = “The request is invalid. Details: Cannot find nested property ‘properties’ on the resource type ‘Microsoft.Azure.Search.V2023_11_01.IndexDefinition’.”
I think this is because when using ChatGPT to convert the python code in the Azure Open AI Search sample into a REST API call, ChatGPT infused an ARM schema design principle where much of the service specific configuration is embedded in a properties bag. That meant that I had the following:
request_body = jsonencode({
properties = {
fields = []
vectorSearch = {}
semantic = {}
}
})
When I really should have had this:
request_body = jsonencode({
fields = []
vectorSearch = {}
semantic = {}
})
After removing the properties wrapper I started getting actual schema errors. These seem like the stemmed from ChatGPT using an old version of the schema. I changed the API version from 2023–11–01 to the latest which is 2025–09–01. But after switching the API version to the latest (2025-09-01), a new error emerged:
create_index_error_message = “The request is invalid. Details: The property ‘vectorSearchDimensions’ does not exist on type ‘Microsoft.Azure.Search.V2023_11_01.SchemaField’ or is not present in the API version ‘2023–11–01’. Make sure to only use property names that are defined by the type.”
But I am still getting schema errors. It seems vectorSearchDimensions turns into dimensions.
{
name = "contentVector"
type = "Collection(Edm.Single)"
searchable = true
retrievable = false
dimensions = 1536
vectorSearchProfile = "contentVector-profile"
}
Now I run Terraform apply again and I discover the next error hiding in the fog of war:
create_index_error_message = “The request is invalid. Details: Cannot find nested property ‘contentFields’ on the resource type ‘Microsoft.Azure.Search.V2025_09_01.PrioritizedFields’.”
create_index_response_raw = <sensitive>
create_index_status_code = “400”
Again, schema changes, this time contentFields changed into prioritizedContentFields. So i change the configurations to this:
semantic = {
defaultConfiguration = "default"
configurations = [
{
name = "default"
prioritizedFields = {
titleField = { fieldName = "sourcepage" }
prioritizedContentFields = [{ fieldName = "content" }]
}
}
]
}
Up next is a complete restructuring of the compression object. truncationDimension and rescoringOptins are now top level attributes.
create_index_error_message = “The request is invalid. Details: Cannot find nested property ‘parameters’ on the resource type ‘Microsoft.Azure.Search.V2025_09_01.VectorSearchAlgorithmConfiguration’.”
create_index_response_raw = <sensitive>
create_index_status_code = “400
Now there is a change in an allowed value. My rescoringStorageMethod had a value of PreserveOriginals but now the service is squaking over the capital P — preferring a camel case version of the magic string.
create_index_error_message = “The request is invalid. Details: Requested value ‘PreserveOriginals’ was not found.”
I finally hit my head on the last wall in this lovely game of data plane whack-a-mole. In the Vector Search Profile the algorithmConfigurationName has become the more concise algorithm.
create_index_error_message = “The request is invalid. Details: The property ‘algorithmConfigurationName’ does not exist on type ‘Microsoft.Azure.Search.V2025_09_01.VectorSearchProfile’ or is not present in the API version ‘2025–09–01’. Make sure to only use property names that are defined by the type.”
create_index_response_raw = <sensitive>
create_index_status_code = “400”
That’s it! Right? Well, I hope.
Solving Authentication with a Rotating Time Tick
Another challenge was dealing with Azure Active Directory (AAD) tokens. Terracurl doesn’t automatically refresh tokens, so I had to manually manage expiration by introducing a time-based trigger.
Error: Unexpected Response Code
│
│ with terracurl_request.create_search_index,
│ on main.tf line 35, in resource “terracurl_request” “create_search_index”:
│ 35: resource “terracurl_request” “create_search_index” {
│
│ Received status code: 401
so i had to refresh my token. i did this by introducing a rotating time resource.
resource "time_rotating" "aad_tick" {
rotation_minutes = 45
}
Then I used this rotating value in a benign header to force terracurl to resend the AAD token request every 45 minutes:
resource "terracurl_request" "aad_token" {
name = "get-token"
method = "POST"
url = "https://login.microsoftonline.com/${var.tenant_id}/oauth2/v2.0/token"
headers = {
Content-Type = "application/x-www-form-urlencoded"
Tick = time_rotating.aad_tick.rfc3339
}
# x-www-form-urlencoded body
request_body = join("&", [
"grant_type=client_credentials",
"client_id=${var.client_id}",
"client_secret=${urlencode(var.client_secret)}",
"scope=${urlencode("https://search.azure.com/.default")}"
])
response_codes = [200]
}
The Final Working Configuration
After ironing out every API inconsistency, undocumented field, and validation edge case, I arrived at a configuration that finally succeeded with a 201 Created:
resource "terracurl_request" "create_search_index" {
name = local.index_name
method = "POST"
url = "${var.search_service_endpoint}/indexes?api-version=2025-09-01"
headers = {
Authorization = "Bearer ${local.aad_access_token}"
Content-Type = "application/json"
}
# The request body is exactly the JSON you provided
request_body = jsonencode({
name = local.index_name
fields = [
{ name = "id", type = "Edm.String", key = true },
{ name = "content", type = "Edm.String", searchable = true, analyzer = "en.lucene" },
{ name = "category", type = "Edm.String", filterable = true, facetable = true },
{ name = "sourcepage", type = "Edm.String", filterable = true, facetable = true },
{ name = "sourcefile", type = "Edm.String", filterable = true, facetable = true },
{ name = "storageUrl", type = "Edm.String", filterable = true },
{ name = "oids", type = "Collection(Edm.String)", filterable = true },
{ name = "groups", type = "Collection(Edm.String)", filterable = true },
{
name = "contentVector"
type = "Collection(Edm.Single)"
searchable = true
retrievable = false
dimensions = 1536
vectorSearchProfile = "contentVector-profile"
}
]
vectorSearch = {
algorithms = [
{ name = "hnsw_config", kind = "hnsw", hnswParameters = { metric = "cosine" } }
]
profiles = [
{
name = "contentVector-profile"
algorithm = "hnsw_config"
compression = "contentVector-compression"
}
]
compressions = [
{
name = "contentVector-compression"
kind = "binaryQuantization"
truncationDimension = 1024
rescoringOptions = {
enableRescoring = true
defaultOversampling = 10
rescoreStorageMethod = "preserveOriginals"
}
}
]
}
semantic = {
defaultConfiguration = "default"
configurations = [
{
name = "default"
prioritizedFields = {
titleField = { fieldName = "sourcepage" }
prioritizedContentFields = [{ fieldName = "content" }]
}
}
]
}
})
# Accept 201/200 as success
response_codes = [200, 201]
# Ensure the token is available first (if it’s another terracurl_request)
# depends_on = [terracurl_request.aad_token]
# --- Destroy semantics: DELETE the index
destroy_method = "DELETE"
destroy_url = "${var.search_service_endpoint}/indexes/${local.index_name}?api-version=2023-11-01"
destroy_headers = {
Authorization = "Bearer ${local.aad_access_token}"
}
}
Missing Visibility in Azure Activity Log
Despite successfully creating the index, I noticed these operations did not appear in the Azure Activity Log. This suggests that data plane activities may not be tracked by default unless Diagnostic Settings for Azure Monitor are explicitly configured. This is an important point for operational visibility and auditing.
Additionally, I observed a mysterious container-index that I didn’t explicitly define—possibly something provisioned by the Azure Portal itself, hidden behind the UI abstraction layer.
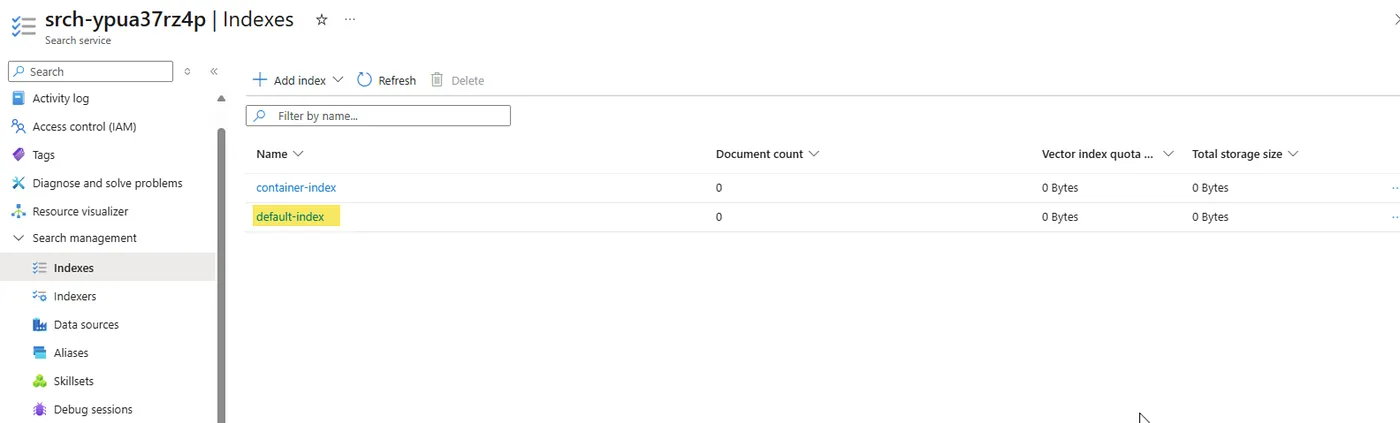
I am not sure what this container-index is. Perhaps this is something that got put there by the Azure Portal’s black magic?
Conclusion
The key takeaway is that Azure AI Search’s data plane resources — like indexes — cannot be managed with ARM templates, and therefore are inaccessible to both Bicep and Terraform’s AzAPI provider. This represents a major limitation in Azure’s Infrastructure-as-Code strategy. Without ARM support, there’s no Terraform support either (since Terraform relies on the AzureRM provider, which in turn relies on ARM).
That’s where terracurl steps in. It allows you to define API calls in Terraform when neither ARM nor AzureRM can help. While powerful, it comes with trade-offs: you must manage your own AAD tokens, work through undocumented schema quirks, and lack telemetry unless explicitly enabled.
This workaround is viable, but it shouldn’t be necessary. Azure must provide full IaC support — including data plane resources — for its cloud services. Until then, terracurl is the tool you didn’t know you needed.
